Mari kita bayangkan andai ada sebuah percobaan yang kejadian yang mungkin terjadi nya belum kita ketahui pada saat awal.
Semua kejadian yang mungkin terjadi pada percobaan tersebut lalu kita kumpulkan menjadi sebuah kumpulan atau himpunan. Maka kumpulan atau himpunan semacam ini kita sebut dengan Ruang Sample dari suatu percobaan dan biasanya ditandai dengan notasi S.
Contoh, Misalkan ada sebuah balapan kuda yang diikuti oleh 7 ekor kuda. Masing-masing kuda yang diberi nomor punggung 1 hingga 7, maka :
S = { semua urutan dari (1, 2, 3, 4, 5, 6, 7) }
Pemunculan urutan (3,4,1,7,6,5,2) akan berarti bahwa, kuda dengan nomor punggung 3 akan datang paling dulu, baru kemudian disusul oleh kuda nomor 4 dan seterusnya.
Semua himpunan bagian A dari Ruang Sampel disebut sebagai kejadian (event). Karena itu, sebuah kejadian adalah sebuah kumpulan yang mengandung peristiwa yang mungkin muncul dalam suatu percobaan. Jika peristiwa kejadian yang muncul dalam percobaan itu terdapat di dalam A, kita katakan bahwa kejadian A terjadi.
Contoh : A = { semua kejadian di S yang didahului oleh 5 }
Maka A adalah semua peristiwa, dimana kuda nomor 5 yang masuk finish paling dulu.
Untuk sembarang kejadian A dan B, misalkan kita menentukan kejadian baru \(A\cup B\) , yang disebut juga union/gabungan A dan B, gabungan ini mengandung semua kejadian yang mungkin muncul yang mungkin saja berada di dalam A atau di dalam B atau berada dikeduanya A dan B. Sejalan dengan hal tersebut, kita tentukan kejadian, AB, yang disebut sebagai irisan/ intersection dari A dan B, dimana kejadian AB terjadi jika A dan B juga terjadi. Kita juga bisa menentukan gabungan dan irisan untuk lebih dari 2(dua) kejadian. Gabungan dari kejadian-kejadian \(A_1, \cdots , A_n\) ditulis \(\bigcup_{i=1}^{n} = A_i\) ditentukan memuat semua kejadian yang berada di sembarang \(A_i\). Begitu pula dengan irisan dari kejadian-kejadian \(A_1, \cdots , A_n\) ditulis dengan \(A_1A_2 \cdots A_n\) yang mengandung semua kejadian yang mungkin muncul (outcome) berada di semua \(A_i\).
Untuk semua kejadian A ada kejadian yang disebut \(A^c\) , sering disebut sebagai komplemen dari A. mengandung semua kejadian di ruang sample S tapi tidak berada di A. Karena itu, \(A^c\) terjadi jika dan hanya jika A tidak terjadi. Karena kejadian yang mungkin muncul haruslah berada di ruang sample S, akibatnya \(S^c\) tidak mengandung kejadian apapun, karenanya tidak muncul apapun. Kita sebut \(S^c\) himpunan null dan ditulis dengan 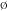 . Jika
. Jika 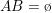 , dikatakan bahwa A dan B mutualy exclusive
, dikatakan bahwa A dan B mutualy exclusive

